每日经济新闻大模型评测报告(第2期):国产“黑马”逆袭,计算能力差成通病

在每日经济新闻于6月25日发布的《每日经济新闻大模型评测报告》第1期中,15款国内外主流大模型在“财经新闻标题创作”“微博新闻写作”“文章差错校对”“财务数据计算与分析”四大实战场景进行了比拼。
随着大模型的迭代更新和大模型新秀的涌现,《每日经济新闻大模型评测报告》第2期如期而至。
第2期评测延续首期评测的宗旨,立足实战,力求为用户展现大模型在具体工作场景中的真实表现,为用户在工作、学习和生活中选择最佳大模型助手提供可靠参考。
本期评测设置了三个应用场景:(1)金融数学计算;(2)商务文本翻译;(3)财经新闻阅读。
每经大模型评测小组为每个场景制定了相应的评价维度和评分指标。每日经济新闻10名资深记者、编辑根据评价维度和评分指标,对各款大模型在三大场景中的表现进行评分,汇总各场景得分,最终得到参评大模型总分。
不同于首期,第2期评测中的任务以客观题为主,绝大多数题目都有标准答案。同时,评价维度和评分标准也更加突出客观性,尽量避免主观性评价。
需要特别指出的是,本期评测是通过各款大模型的API端口,并在默认温度下完成。与公众用户使用的大模型C端对话工具存在差异。但评测结果对用户在具体场景中选择合适的大模型工具,依然具有重大参考价值。
本期评测在“雨燕智宣AI创作+”测试台上进行,参评模型包括GPT-4o、智谱GLM-4、百度文心ERNIE-4.0-Turbo等15款国内外明星大模型。
本期评测时间为2024年8月12日,因此上述参评大模型中的所有国内大模型均为截至8月12日的最新版本。

谁能在三大评测场景中脱颖而出?
经过激烈角逐,评测结果新鲜出炉!
报告完整版以及测评题目,评分指标细则及部分案例,可访问:每日经济新闻大模型评测报告(第2期)。

评测结果显示,“黑马”幻方求索DeepSeek-V2以237.75的总分位居榜首,紧随其后的是腾讯混元hunyuan-pro(237.08分)和Anthropic Claude 3.5 Sonnet(234.42分)。
在专项能力方面,各模型展现出了不同的优势。
金融数学计算方面,腾讯混元hunyuan-pro以78分的成绩领先其他模型,排名第一,幻方求索DeepSeek-V2和商汤商量SenseChat V5.5紧随其后。相比之下,零一万物的Yi-Large、百度的文心ERNIE-4.0-Turbo以及昆仑天工的SkyChat-3.0则在金融数学计算方面表现稍显逊色,分别位列倒数第三、倒数第二与倒数第一的位置。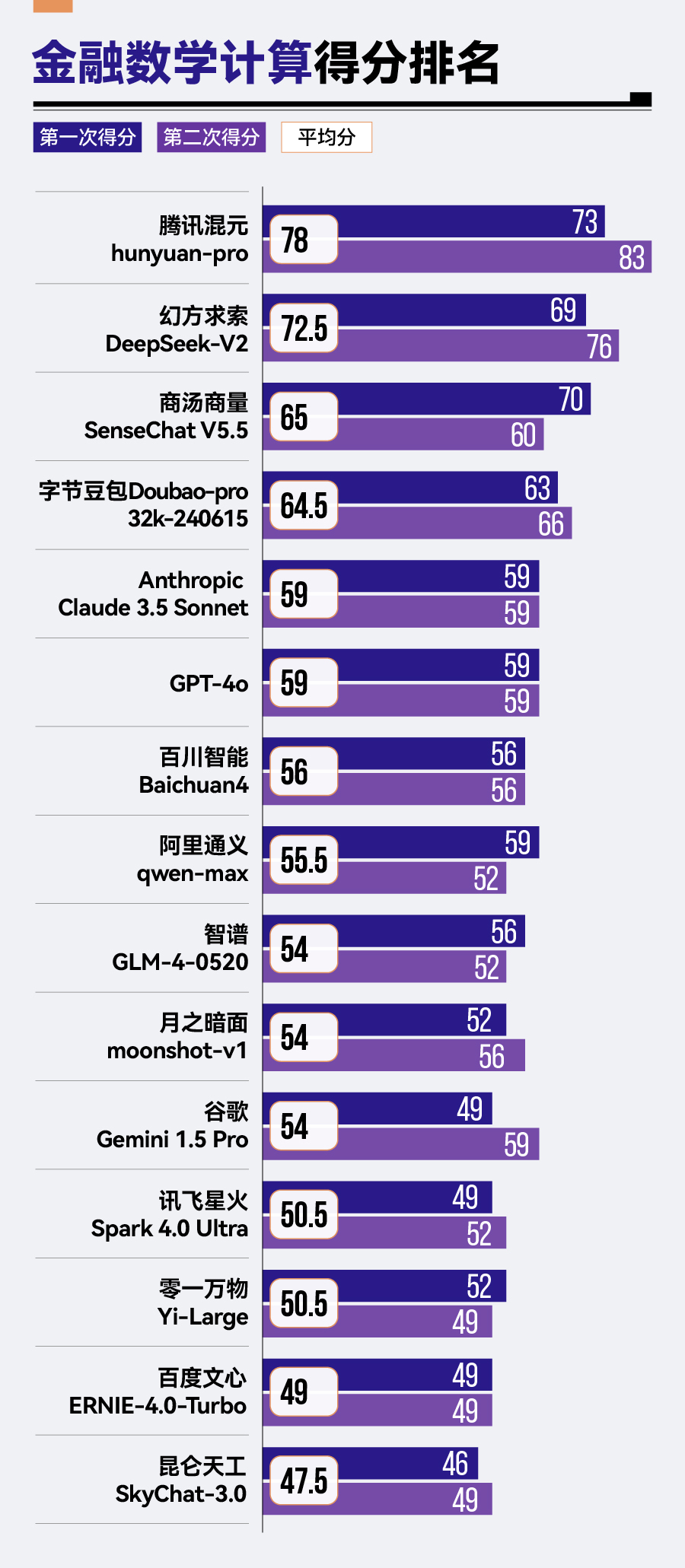
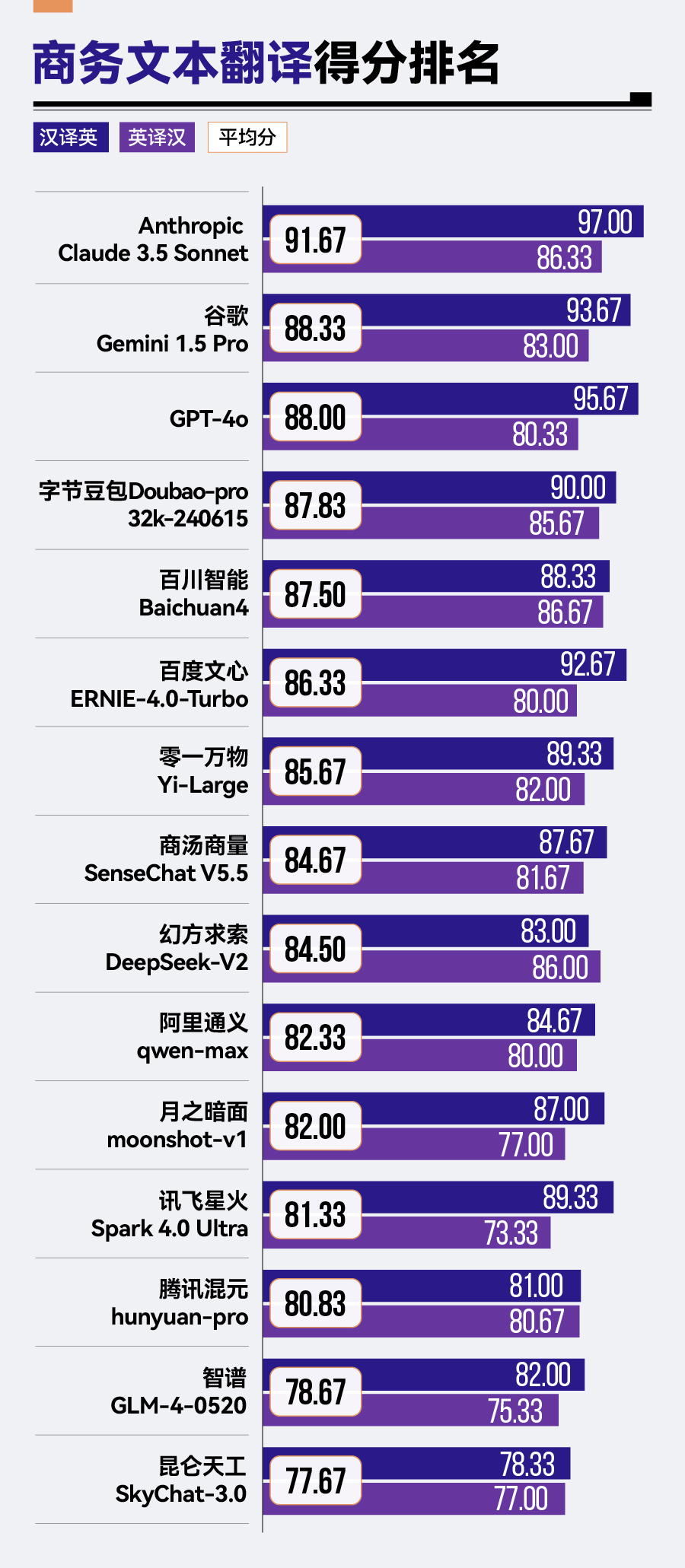
商务文本翻译场景中,Anthropic Claude 3.5 Sonnet凭借其91.67分的卓越成绩,显著领先于其他竞争对手,谷歌Gemini 1.5 Pro、GPT-4o及字节豆包Doubao-pro-32k紧随其后,展现了不俗的翻译实力。然而,腾讯混元hunyuan-pro、智谱GLM-4与昆仑天工SkyChat-3.0在该场景下的表现则稍显逊色,分别位于榜单的后三位。
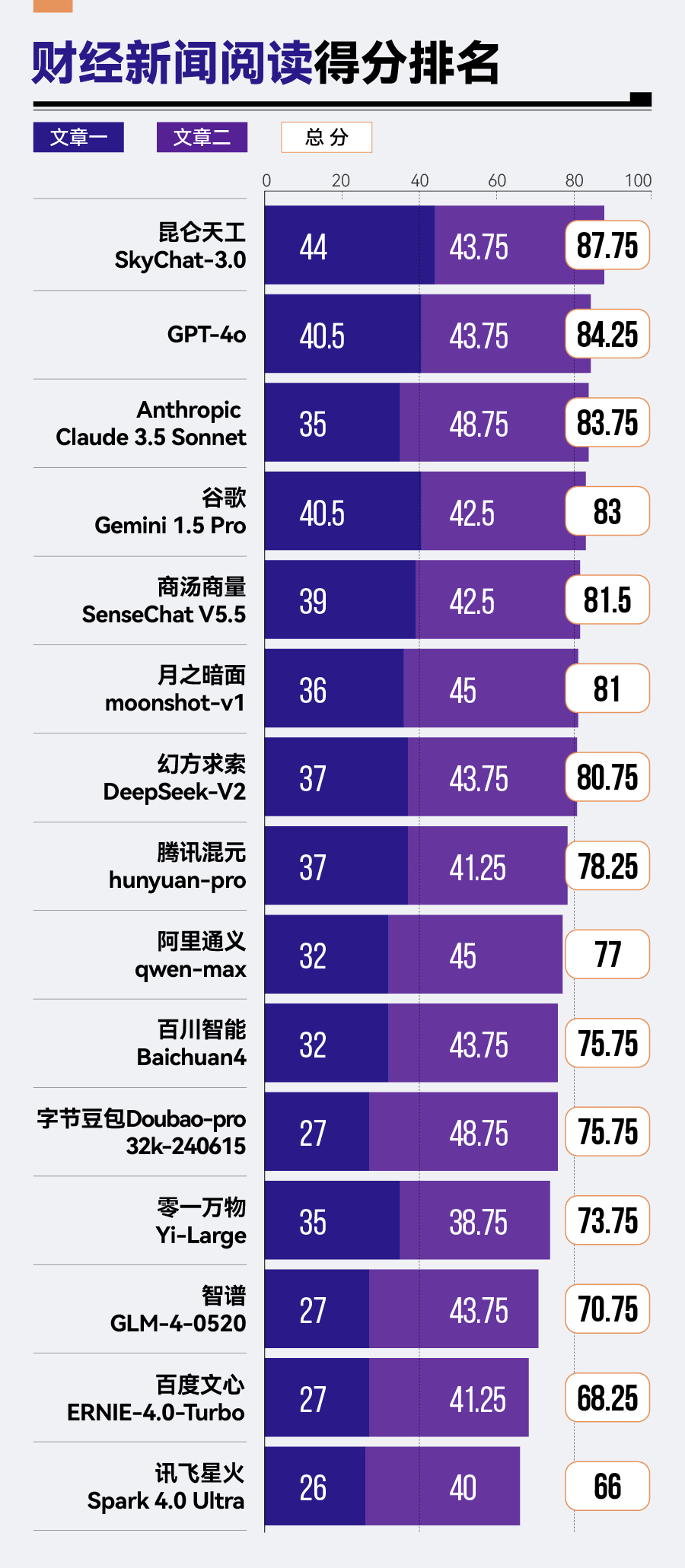
转至财经新闻阅读场景,昆仑天工SkyChat-3.0以87.75分的佳绩拔得头筹,GPT-4o与Anthropic Claude 3.5 Sonnet紧随其后。相比之下,智谱GLM-4、百度文心ERNIE-4.0-Turbo及讯飞星火Spark 4.0 Ultra在此方面的表现则稍显不足,分列该场景排名的后三位。
结论一:大模型之间差距明显
本次评测结果显示,幻方求索DeepSeek-V2、腾讯混元hunyuan-pro、Anthropic Claude 3.5 Sonnet、GPT-4o和商汤商量SenseChat V5.5构成第一梯队。值得注意的是,排名靠前的模型中,国产大模型表现突出,与顶级海外模型实力相当。
然而,从第一名幻方求索DeepSeek-V2(237.75分)到第十五名讯飞星火Spark 4.0 Ultra(197.83分),总分差距达到了近40分,反映出大模型间仍存在显著差距。
结论二:数学计算能力成普遍短板
各款大模型数学计算方面普遍存在不足。
15款参评模型中,仅有腾讯混元hunyuan-pro、幻方求索DeepSeek-V2、商汤商量SenseChat V5.5、字节豆包Doubao-pro-32k这4款大模型超过60分。即使是在其他场景表现出色的模型,如Anthropic Claude 3.5 Sonnet和GPT-4o,在此项测试中也仅得到59分。
具体而言,腾讯混元hunyuan-pro表现较为突出,从第1期评测这个计算题第六名一跃成为本期第一;字节豆包Doubao-pro-32k从第八名提升到第四名。
同时,经过版本更新的商汤商量SenseChat系列,在第2期评测中也以SenseChat V5.5的新姿态亮相,并实现从原先第十四名到第三名的巨大跨越。
上一期的“黑马”幻方求索DeepSeek-V2依然表现出突出且稳定的计算能力,在两期评测的计算题中均排名第二名。
与之形成鲜明对比的是,零一万物Yi-Large在上期评测的计算题中排名第三,但在此次评测中跌落至倒数第三。
从具体题目分析,对于用一步计算即可得到答案的简单计算题,15款大模型均表现良好。然而,面对计算公式复杂、步骤较多的题目时,不少大模型表现并不理想。
此外,许多大模型在处理特定数学逻辑与表达规范上存在局限。例如,不能准确区分百分数作差结果应采用的正确表示方式——即应该使用百分点而非直接以百分数形式来表达。
结论三:国内大模型需提高外语能力
整体来看,在商务文本翻译场景中,参评大模型表现了较高的翻译水平,平均分达到了84.5分。海外大模型展现出明显优势,包揽了该场景下的前三名。
不过,国内外大模型在英译汉中的得分差距不大,真正使总分拉开差距的是汉译英。Anthropic Claude 3.5 Sonnet、谷歌Gemini 1.5 Pro和GPT-4o在汉译英任务中得分均超过90分。
而国内大模型表现相对逊色,尤其是在“意思准确”与“术语一致性”维度上有待提升。此外,在“意思完整”维度上,幻方求索DeepSeek-V2、昆仑天工SkyChat-3.0相对来说,表现欠佳。而在“细节准确性”维度上,腾讯混元hunyuan-pro、月之暗面moonshot-v1以及字节豆包Doubao-pro-32k的表现有待提升。
结论四:通用大模型各项能力却不均衡
第2期评测与第1期评测的场景、维度和标准不同,导致部分模型排名变化显著。尽管都是通用大模型,但存在各项能力不均衡,“偏科”现象严重的情况。
具体而言,零一万物Yi-Large两期评测的表现波动较大。在第1期评测中,零一万物Yi-Large位居榜首。然而在第2期评测中,其表现大幅下滑,总排名也跌至倒数第四。
本期评测新加入的大模型昆仑天工SkyChat-3.0,在文章阅读及问答中排名第一,但在金融数学计算以及商务文本翻译中却垫底。
腾讯混元hunyuan-pro的表现则展现了明显的进步。在第1期评测中,其排名相对靠后。但在第2期评测中,腾讯混元hunyuan-pro总分位列第二,尤其在金融数学计算场景中以78分的成绩领先其他大模型。
相比之下,幻方求索DeepSeek-V2在两次评测中都表现出色。在第1期评测中,幻方求索DeepSeek-V2排名第三;而到了第2期评测,更是跃居榜首。在计算能力方面,幻方求索DeepSeek-V2均保持了高水平的发挥。
海外大模型中,Anthropic公司的Claude在两期评测中都表现不俗,但排名有所变动。在第1期中,Anthropic Claude 3 Opus排名第二;在第2期中,Anthropic Claude 3.5 Sonnet尽管在商务文本翻译任务中表现出色,但总体排名略有下降,排在第三位。
每日经济新闻大模型评测小组
2024年9月
⋯⋯⋯⋯
未来,每日经济新闻将基于评测报告,精选各场景下的优秀大模型,开发相应的功能,在每经App上线,为用户带来高效、高质的AI工具与全新体验。
同时,“每日经济新闻大模型评测小组”将继续深入探索大模型的无限可能,从实际应用场景出发,对各个大模型进行全方位的评测,并定期推出专业报告,带来最前沿的洞察和发现。
在此,我们诚挚地邀请您,加入评测项目。
如果您是研发企业,想要展示自家大模型的实力,与其他大模型进行比拼,请将参评大模型的详细信息发送至我们的邮箱:[email protected]。
如果您是大模型的使用者,请告诉我们您希望在哪些场景中使用大模型,或者希望我们测试大模型的哪些能力。打开每日经济新闻App,在“个人中心”——“意见反馈”栏中留下您的想法和需求。
期待您的参与,共同探索大模型的无限可能。

免责声明:本文章由会员“极目新闻”发布如果文章侵权,请联系我们处理,本站仅提供信息存储空间服务如因作品内容、版权和其他问题请于本站联系